





杏彩体育登录_项目案例:基于YOLO的铝型材表面缺陷识别
来源:杏彩体育官网app模型的铝型材表面缺陷识别方法。而建立基于 YOLO 的铝型材表面缺陷识别模型,通过增加模型预测尺度,提高对微小缺陷的识别能力。通过多尺度训练方法,增强模型对不同尺度缺陷的适应性和识别精度。
铝型材作为建筑和领域中重要的应用材料,其全行业的产量和消费量在世界范围内逐年递增。铝型材在生产过程中,由于材料特性和加工工艺,不可避免存在表面缺陷,严重影响铝型材的可靠性、安全性和可加工性。在实际生产中,对铝型材表面缺陷进行准确快速识别,对保证铝型材的质量至关重要。传统的铝型材表面缺陷识别方法包括涡流检测法、超声导波检测及红外检测法等识别成本高、设备复杂,且不易实现缺陷识别过程的可视化。机器视觉检测作为一种非接触式在线自动检测技术,具有非接触、安全性高、识别效率高和工作时间长的特点,是实现表面缺陷准确与快速识别的有效手段。
例如,胡继文等针对带有纹理的铝型材图像,提出基于 Gabor 滤波的纹理分析方法,实现铝型材喷涂表面图像快速分类,但该方法极易受到喷涂表面粗糙度的影响。刘泽等针对钢轨表面典型的缺陷图像设计动态阈值分割算法和缺陷区域提取算法,优先实现钢轨缺陷的检测。孙雪晨等设计了一种基于机器视觉的凸轮轴表面缺陷识别系统,能够有效识别与定位 1 mm 以上的缺陷。以上识别
方法多采用传统机器视觉算法,通过图像形态学处理与特征提取进行缺陷识别,往往需要根据不同形态的缺陷特征,设计不同的特征提取与识别算法。铝型材表面缺陷形态不规则、位置随机且大小不一,采用传统机器视觉缺陷识别方法进行铝型材缺陷识别,难以同时满足检测精度与效率的要求。
近些年,随着人工智能技术的发展,基于深度学习的目标识别方法在工业零件的缺陷识别中得到应用,并取得较好的效果。YOLO( You Only Look Once) 识别算法是目前深度学习领域执行速度较优算法,其将目标识别问题转化为回 归问题可以同时预测多个识别框的位置和类别,具备较高准确率和执行速度。在 YOLO 的基础上,又出现 YOLOv2、YOLOv3改进算法,在识别速度和准确率上有所提高。其中,YOLOv3 对不同大小的多尺度目标识别效果较好,在齿轮、玻璃外观等表面缺陷识别领域得到应用。深度学习的识别方法用于工业产品的缺陷识别,具有较好的泛化性和鲁棒性。
目前,铝型材表面缺陷的识别方法多采用传统的缺陷识别技术,将 YOLO 深度学习模型用于铝型材识别,将有助于改善铝型材表面缺陷识别的准确率与速度,提高铝型材的产品质量与生产效率。针对铝型材表面缺陷快速准确识别的需求,本文提出一种基于 YOLO 深度学习模型的铝型材表面缺陷识别方法。
首先,采用图像增广对原始图像进行扩充,解决原始数据集中图像数量少且缺陷数据不均衡问题,并构建 3 个不同分辨率的数据集,提高训练过程中对不同尺度图像的鲁棒性。然后,建立铝型材表面缺陷的 YOLO 识别模型,通过增加模型预测尺度,提高对微小缺陷的识别能力。最后,对铝型材缺陷数据集的目标框重新进行聚类分析,并利用多尺度训练的方法,在低分辨率数据集上进行预训练,再利用中高分辨率数据集微调识别模型,以增强模型的适应性和准确率。
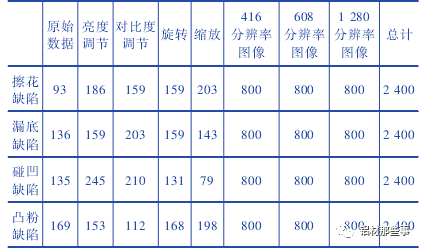
如图 1 所示,铝型材常见的缺陷有 4 种,分别是擦花、漏底、碰凹、凸粉。本文的铝型材图像数据集来源于江苏省某铝材公司。原始的铝型材图像数据集一共包括 342 张铝型材缺陷图像,缺陷图像样本较少,且部分缺陷占整个数据集比例过小、缺陷数据不均衡。深度学习在进行训练时,如果数据集较少会导致模型出现过拟合的问题。为解决上述问题,本文对有缺陷的铝型材图像,采用图像增广来进行数据集扩充。图像增广技术是对原图像数据进行一系列随机对比度调整、旋转等处理,产生相似但不同的训练数据,以扩大训练图像集的规模,同时降低模型对某些特征的依赖,提高模型的泛化能力。

本文采用的图像增广方法包括调整对比度、亮度、旋转和缩放,每张增广后的图片为原图经过多种随机组合变换得到。图像增广后每种缺陷类别的图像的数量为 2 400 张,各缺陷比例为 1∶ 1∶ 1∶ 1。训练集的图像被转换为 PASCAL-VOC格式,其长度分别调整为 416、608、1 280,并调整宽度以保持原始纵横比。整个铝型材图像数据集的图片为 9 600 张,如表 1 所示。与一般的图像分类数据集不同,铝型材数据集在进行深度学习训练时,需提供图片缺陷区域的坐标位置。本文中通过 labellmg 软件来进行缺陷位置的标注。铝型材数据集中擦花、漏底、碰凹、凸粉四种缺陷分别标注,并保存其路径、标签和缺陷坐标信息。
YOLOv3 作为一种基于回归的目标识别算法,能够实现多目标的快速、准确识别。YOLOv3 对输入图像的全局区域进行训练,可加快训练速度且能更好地区分目标和背景。先利用 Darknet-53主干网络完成铝型材表面缺陷特征提取,再采用目标框直接预测目标类别和位置。铝型材表面缺陷形态不规则、位置随机且大小不一,直接应用 YOLOv3 模型进行识别难以保证微小缺陷的精密识别。本文在深入分析 YOLOv3 模型特性的基础上对其进行改进。将原有 3 尺度识别结构扩展为 4 尺度,提高对微小缺陷的识别能力; 通过重新聚类分析构建适合铝型材表面缺陷的初始目标框,改进 YOLO 算法的模型参数; 采用多尺度训练方式对训练流程进行优化,以增强模型对不同尺度缺陷的适应性和识别精度,解决铝型材表面缺陷识别困难、精度低等问题。
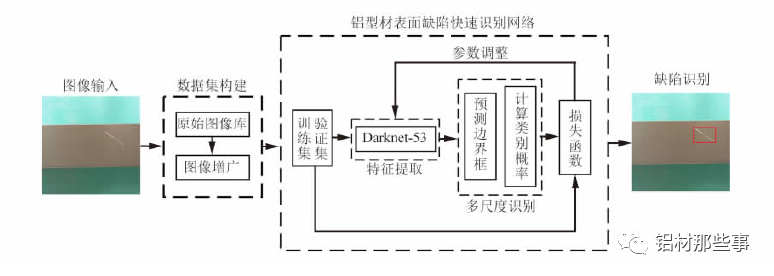
基于 YOLO 的铝型材多尺度识别模型架构如图 2 所示。在数据集构建后,以 Darknet-53 为主干网络进行特征提取,并融合多尺度识别,实现铝型材表面缺陷的有效识别。该网络从训练集和验证集中快速提取铝型材表面缺陷相应特征,并融合多尺度特征信息,同时得到缺陷预测框和类别,从而快速精确地识别出缺陷种类和位置。其中,训练集用于拟合识别网络,验证集用于调整识别网络的超参数以及对网络性能进行评估。
铝型材表面缺陷识别模型的工作流程如下: 首先,构建铝型材表面缺陷图像数据集,将缺陷图像输入识别模型进行训练; 再根据预测边界框及所属类别的概率对缺陷进行多尺度预测; 最后通过损失函数不断调整训练参数,以得到改进后识别模型的参数。
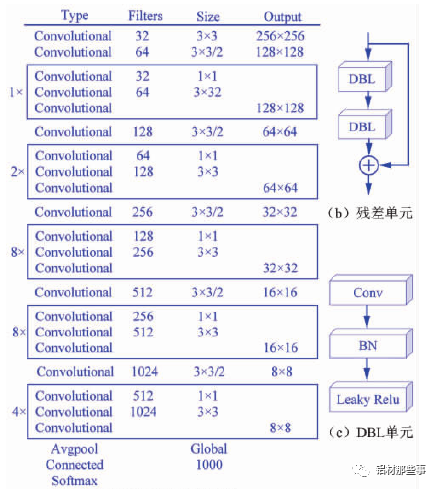
采用 Darknet-53 网络作为图像特征提取的主干网络,其网络结构如图 3( a) 所示。整个网络采用完整的卷积层,没有池化层和固定输出的连接层。Darknet-53 网络结构借鉴残差神经网络Res Net( ResidualNetwork),在其网络中加入 5 个残差块( residual) 。每个残差块中包含不同数量的残差单元,残差单元由特征提取层与两个 DBL( Darknetconv2d BN Leaky) 单元经过两层卷积所构成,如图 3( b) 所示。其中,残差单元中的 DBL 单元也是YOLOv3 的基本构成单元,由卷积( Conv) 、批归一化( BN) 和激活函数 Leaky Relu 共同构成,如图 3( c) 所示。Darknet-53网络中加入残差单元,可以保证主网络结构在不断加深的情况下不会造成梯度消失或爆炸,以加强主网络对图像特征的提取效果,进而提高模型识别的准确率。
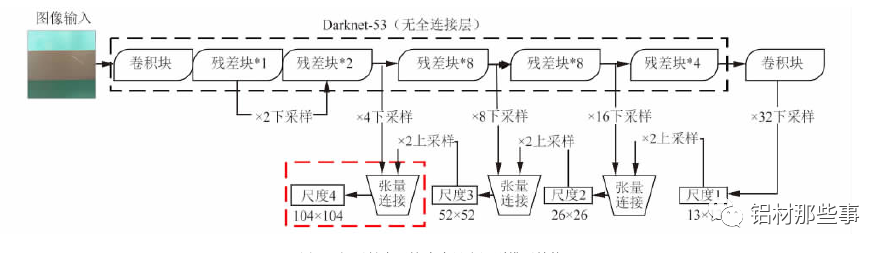
对于大多数卷积神经网络,通过特征提取网络获取图像最终的特征图后,直接在该特征图上进行预测。这种方式仅能获取图像中单一尺度的语义信息,识别的尺度范围有限。在铝型材表面缺陷识别过程中,缺陷区域往往大小不一,且具有不同特征,因而需要利用不同尺度的识别网络来适应多尺度目标。YOLOv3 通过多尺度预测的方式对不同尺寸的目标来识别,其结构如图 4 所示。以本文的研究对象铝型材为例,输入的图像经过 Dark-net-53 主干网络时,共进行 5 次下采样。每进行一次下采样,铝型材的特征图就会变成原输入图像尺寸一半。经过 5 次即 32 倍下采样后,生成尺度 1 的铝型材特征图。
该尺度特征图为 13 ×13 分辨率,通过卷积等操作后进行一次 2 倍上采样,生成 26 ×26 分辨率的特征图,将其与特征提取网络中16 倍下采样生成的 26 × 26 分辨率的特征图进行张量连接。通过张量连接融合两个图像的特征信息,生成一个双尺度融合的铝型材特征图( 尺度 2) 。
以此类推,该尺度特征图再次通过 2 倍上采样,与 8 倍下采样生成的 52 × 52 分辨率的特征图进行张量连接,生成同为 52 × 52 分辨率且 3 尺度融合的铝型材特征图( 尺度 3) 。在铝型材缺陷识别中,存在微小的缺陷区域,使用原YOLOv3 中多尺度预测的方法难以满足微小缺陷精确识别的需求。
针对该问题,本文对 YOLOv3 模型进行改进,将原有 3个尺度识别扩展为 4 个尺度,增加 104 × 104 分辨率的特征图,见图 4 新加结构。该尺度通过张量连接的方式,将 4 倍下采样生成的 104 ×104 分辨率的特征图与尺度 3 中 52 × 52分辨率的特征图融合。通过多尺度特征融合方式,将不同分辨率的特征图融合后单独输出且分别进行目标预测,以此提升小目标识别的精确度。融合后的尺度 4 包含之前各尺度信息的特征图,可改善铝型材表面微小缺陷的识别效果。

目标框( anchor boxes) 是一组具有固定宽高比的数据集图像初始候选框,其设定对图像检测的精度和处理速度有着重要影响。YOLO 算法对目标框的宽高比维度进行 K-menas聚类分析,并对神经网络的训练过程进行优化,即事先确定一组宽高比维度固定的矩形框作为选取目标包围框时的参照物,通过预测目标框的偏移量取代直接预测坐标,以降低模型训练的复杂度。在 YOLOv3 原模型中,目标框通过 Pas-cal VOC、COCO 等图像标准数据集聚类得到,适用于自然场景中的目标。
本文要识别的目标为铝型材表面缺陷,这些缺陷的特征与上述数据集中的目标完全不同,因此直接使用原算法中聚类分析过的目标框并不合理。基于上述考虑,为得到精准的铝型材缺陷位置和类别信息,本文利用 K-menas 算法对数据集中目标框的宽高比维度重新进行聚类分析,得到适合铝型材数据集的目标框。通过聚类分析主要是获得更高的交并比 Io U( Averange intersection over union) 。Io U 代表预测的目标框与真实目标框的重叠率,其值越大表示聚类效果越好。因。
